

AMD e Intel utilizan la arquitectura ARM x86 para reducir la brecha en IA con ACE, integrando motores de multiplicación de matrices y formatos de baja precisión directamente en las futuras CPU.
- Masterbitz

- hace 3 horas
- 3 min de lectura
ACE, el próximo conjunto de extensiones x86 definidas tanto por AMD como por Intel, ha visto la última versión de las especificaciones, centrada en la aceleración de la IA.

AMD e Intel se enfocan en la aceleración de la IA a través de arquitecturas x86 de próxima generación que cumplen con ACE
El año pasado, Intel y AMD se asociaron para fortalecer el ecosistema x86 a través de la iniciativa "x86 Ecosystem Advisory Group". El plan era ofrecer un conjunto estandarizado de características en todas las arquitecturas para hacer x86 accesible, escalable y compatible con los requisitos futuros. Se anunciaron cuatro características clave: FRED, AVX10, ChkTag y ACE.
Ahora, las últimas especificaciones de ACE "AI Compute Extensions" han sido publicadas por AMD e Intel, que nos dan una idea de lo que esta nueva característica para los chips x86 tiene para ofrecer.
Las extensiones de computación AI (o ACE) para arquitecturas x86 tienen como objetivo ofrecer un aumento significativo en el rendimiento de la multiplicación de la matriz, al tiempo que ofrecen escalabilidad y eficiencia energética. Como sabemos, Matrix Multiplication es el bloque central de las redes neuronales y los LLM en las cargas de trabajo de IA.

Las extensiones SIMD (instrucción única, datos múltiples) actuales, como AVX10, pueden hacer la multiplicación de matriz, pero su escalabilidad y densidad de cálculo pueden ser limitadas. Técnicas como la multiplicación de matriz acelerada pueden conducir a un mayor rendimiento, pero este no es un enfoque eficiente. El EAG tiene como objetivo resolver esto a través de ACE con la multiplicación de matrices acelera la multiplicación al tiempo que ofrece una mayor flexibilidad y escalabilidad.
Las extensiones ACE definen primitivas de multiplicación de matrices que aumentan AVX y código escalar con nuevas capacidades, añadiendo: Estado de registro ACE, incluyendo registros de escala de mosaico y bloque Operaciones de procesamiento de datos que consumen la entrada del registro AVX y operan en el estado del registro de mosaicos Los datos mueven las operaciones para mover los datos entre el estado del registro ACE y los registros AVX Estado y operaciones para la gestión de sistemas ACE proporciona una estrecha integración entre los vectores AVX y los registros de mosaicos ACE, combinando operaciones de procesamiento de azulejos de alta densidad de computación con las características completas de procesamiento de datos de AVX. Además de la aceleración de la matriz, se proporcionan una serie de operaciones de conversión de formato dedicado en el marco AVX10. Vía x86 EAG
Estas últimas especificaciones definen extensiones x86 para acelerar las tareas de computación, centrándose inicialmente en los núcleos de multiplicación de matrices y formatos de datos de precisión reducidos importantes para las cargas de trabajo de ML.
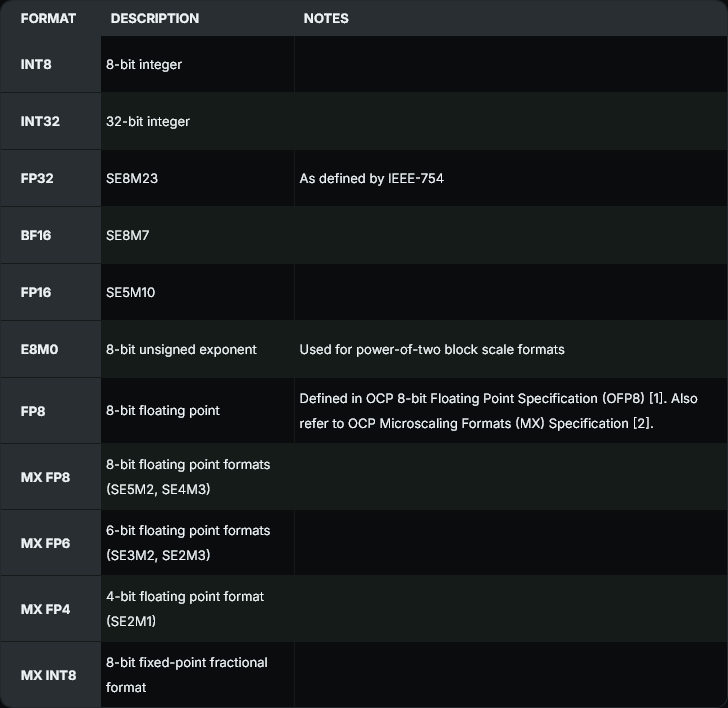
Formatos de datos
Las extensiones descritas en este documento incluyen soporte para varios formatos de datos. Esto puede incluir soporte de formato nativo para operaciones tales como multiplicación de matriz, soporte de escalado para operaciones de estilo MX OCP, formato de acumulación y soporte de conversión de formato entre diferentes formatos. El soporte para formatos de datos adicionales puede introducirse en el futuro.
ACE es solo un paso en el camino hacia adelante para x86. También hemos hablado de APX (Advanced Performance Extensions), que jugará un papel crucial en el desarrollo de chips de próxima generación con arquitecturas x86. Se espera que estos avances aterricen en futuras alineaciones.
Fuente: Wccftech



.png)



Comentarios